 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordanceGrasp-R1:Leveraging Reasoning-Based Affordance Segmentation with Reinforcement Learning for Robotic Grasping
Feb 03, 2026We introduce AffordanceGrasp-R1, a reasoning-driven affordance segmentation framework for robotic grasping that combines a chain-of-thought (CoT) cold-start strategy with reinforcement learning to enhance deduction and spatial grounding. In addition, we redesign the grasping pipeline to be more context-aware by generating grasp candidates from the global scene point cloud and subsequently filtering them using instruction-conditioned affordance masks. Extensive experiments demonstrate that AffordanceGrasp-R1 consistently outperforms state-of-the-art (SOTA) methods on benchmark datasets, and real-world robotic grasping evaluations further validate its robustness and generalization under complex language-conditioned manipulation scenarios.
Language-Guided Grasp Detection with Coarse-to-Fine Learning for Robotic Manipulation
Dec 24, 2025Grasping is one of the most fundamental challenging capabilities in robotic manipulation, especially in unstructured, cluttered, and semantically diverse environments. Recent researches have increasingly explored language-guided manipulation, where robots not only perceive the scene but also interpret task-relevant natural language instructions. However, existing language-conditioned grasping methods typically rely on shallow fusion strategies, leading to limited semantic grounding and weak alignment between linguistic intent and visual grasp reasoning.In this work, we propose Language-Guided Grasp Detection (LGGD) with a coarse-to-fine learning paradigm for robotic manipulation. LGGD leverages CLIP-based visual and textual embeddings within a hierarchical cross-modal fusion pipeline, progressively injecting linguistic cues into the visual feature reconstruction process. This design enables fine-grained visual-semantic alignment and improves the feasibility of the predicted grasps with respect to task instructions. In addition, we introduce a language-conditioned dynamic convolution head (LDCH) that mixes multiple convolution experts based on sentence-level features, enabling instruction-adaptive coarse mask and grasp predictions. A final refinement module further enhances grasp consistency and robustness in complex scenes.Experiments on the OCID-VLG and Grasp-Anything++ datasets show that LGGD surpasses existing language-guided grasping methods, exhibiting strong generalization to unseen objects and diverse language queries. Moreover, deployment on a real robotic platform demonstrates the practical effectiveness of our approach in executing accurate, instruction-conditioned grasp actions. The code will be released publicly upon acceptance.
TUMTraf EMOT: Event-Based Multi-Object Tracking Dataset and Baseline for Traffic Scenarios
Dec 20, 2025In Intelligent Transportation Systems (ITS), multi-object tracking is primarily based on frame-based cameras. However, these cameras tend to perform poorly under dim lighting and high-speed motion conditions. Event cameras, characterized by low latency, high dynamic range and high temporal resolution, have considerable potential to mitigate these issues. Compared to frame-based vision, there are far fewer studies on event-based vision. To address this research gap, we introduce an initial pilot dataset tailored for event-based ITS, covering vehicle and pedestrian detection and tracking. We establish a tracking-by-detection benchmark with a specialized feature extractor based on this dataset, achieving excellent performance.
BiSeg-SAM: Weakly-Supervised Post-Processing Framework for Boosting Binary Segmentation in Segment Anything Models
Apr 02, 2025



Accurate segmentation of polyps and skin lesions is essential for diagnosing colorectal and skin cancers. While various segmentation methods for polyps and skin lesions using fully supervised deep learning techniques have been developed, the pixel-level annotation of medical images by doctors is both time-consuming and costly. Foundational vision models like the Segment Anything Model (SAM) have demonstrated superior performance; however, directly applying SAM to medical segmentation may not yield satisfactory results due to the lack of domain-specific medical knowledge. In this paper, we propose BiSeg-SAM, a SAM-guided weakly supervised prompting and boundary refinement network for the segmentation of polyps and skin lesions. Specifically, we fine-tune SAM combined with a CNN module to learn local features. We introduce a WeakBox with two functions: automatically generating box prompts for the SAM model and using our proposed Multi-choice Mask-to-Box (MM2B) transformation for rough mask-to-box conversion, addressing the mismatch between coarse labels and precise predictions. Additionally, we apply scale consistency (SC) loss for prediction scale alignment. Our DetailRefine module enhances boundary precision and segmentation accuracy by refining coarse predictions using a limited amount of ground truth labels. This comprehensive approach enables BiSeg-SAM to achieve excellent multi-task segmentation performance. Our method demonstrates significant superiority over state-of-the-art (SOTA) methods when tested on five polyp datasets and one skin cancer dataset.
Towards Vision Zero: The Accid3nD Dataset
Mar 15, 2025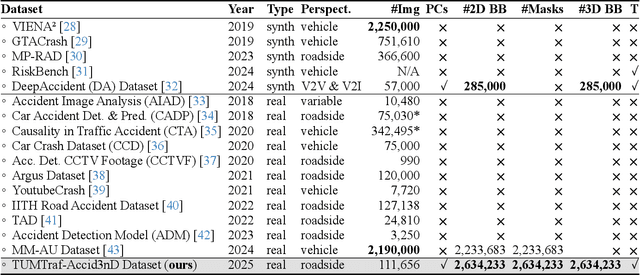
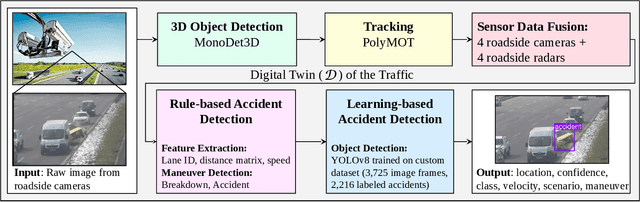


Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as unavoidable and sporadic outcomes of traffic networks. No public dataset contains 3D annotations of real-world accidents recorded from roadside sensors. We present the Accid3nD dataset, a collection of real-world highway accidents in different weather and lighting conditions. It contains vehicle crashes at high-speed driving with 2,634,233 labeled 2D bounding boxes, instance masks, and 3D bounding boxes with track IDs. In total, the dataset contains 111,945 labeled frames recorded from four roadside cameras and LiDARs at 25 Hz. The dataset contains six object classes and is provided in the OpenLABEL format. We propose an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our website: https://accident-dataset.github.io.
CoDa-4DGS: Dynamic Gaussian Splatting with Context and Deformation Awareness for Autonomous Driving
Mar 09, 2025



Dynamic scene rendering opens new avenues in autonomous driving by enabling closed-loop simulations with photorealistic data, which is crucial for validating end-to-end algorithms. However, the complex and highly dynamic nature of traffic environments presents significant challenges in accurately rendering these scenes. In this paper, we introduce a novel 4D Gaussian Splatting (4DGS) approach, which incorporates context and temporal deformation awareness to improve dynamic scene rendering. Specifically, we employ a 2D semantic segmentation foundation model to self-supervise the 4D semantic features of Gaussians, ensuring meaningful contextual embedding. Simultaneously, we track the temporal deformation of each Gaussian across adjacent frames. By aggregating and encoding both semantic and temporal deformation features, each Gaussian is equipped with cues for potential deformation compensation within 3D space, facilitating a more precise representation of dynamic scenes. Experimental results show that our method improves 4DGS's ability to capture fine details in dynamic scene rendering for autonomous driving and outperforms other self-supervised methods in 4D reconstruction and novel view synthesis. Furthermore, CoDa-4DGS deforms semantic features with each Gaussian, enabling broader applications.
TUMTraffic-VideoQA: A Benchmark for Unified Spatio-Temporal Video Understanding in Traffic Scenes
Feb 04, 2025



We present TUMTraffic-VideoQA, a novel dataset and benchmark designed for spatio-temporal video understanding in complex roadside traffic scenarios. The dataset comprises 1,000 videos, featuring 85,000 multiple-choice QA pairs, 2,300 object captioning, and 5,700 object grounding annotations, encompassing diverse real-world conditions such as adverse weather and traffic anomalies. By incorporating tuple-based spatio-temporal object expressions, TUMTraffic-VideoQA unifies three essential tasks-multiple-choice video question answering, referred object captioning, and spatio-temporal object grounding-within a cohesive evaluation framework. We further introduce the TUMTraffic-Qwen baseline model, enhanced with visual token sampling strategies, providing valuable insights into the challenges of fine-grained spatio-temporal reasoning. Extensive experiments demonstrate the dataset's complexity, highlight the limitations of existing models, and position TUMTraffic-VideoQA as a robust foundation for advancing research in intelligent transportation systems. The dataset and benchmark are publicly available to facilitate further exploration.
UniLoc: Towards Universal Place Recognition Using Any Single Modality
Dec 16, 2024To date, most place recognition methods focus on single-modality retrieval. While they perform well in specific environments, cross-modal methods offer greater flexibility by allowing seamless switching between map and query sources. It also promises to reduce computation requirements by having a unified model, and achieving greater sample efficiency by sharing parameters. In this work, we develop a universal solution to place recognition, UniLoc, that works with any single query modality (natural language, image, or point cloud). UniLoc leverages recent advances in large-scale contrastive learning, and learns by matching hierarchically at two levels: instance-level matching and scene-level matching. Specifically, we propose a novel Self-Attention based Pooling (SAP) module to evaluate the importance of instance descriptors when aggregated into a place-level descriptor. Experiments on the KITTI-360 dataset demonstrate the benefits of cross-modality for place recognition, achieving superior performance in cross-modal settings and competitive results also for uni-modal scenarios. Our project page is publicly available at https://yan-xia.github.io/projects/UniLoc/.
Dataset Distillation by Automatic Training Trajectories
Jul 19, 2024



Dataset Distillation is used to create a concise, yet informative, synthetic dataset that can replace the original dataset for training purposes. Some leading methods in this domain prioritize long-range matching, involving the unrolling of training trajectories with a fixed number of steps (NS) on the synthetic dataset to align with various expert training trajectories. However, traditional long-range matching methods possess an overfitting-like problem, the fixed step size NS forces synthetic dataset to distortedly conform seen expert training trajectories, resulting in a loss of generality-especially to those from unencountered architecture. We refer to this as the Accumulated Mismatching Problem (AMP), and propose a new approach, Automatic Training Trajectories (ATT), which dynamically and adaptively adjusts trajectory length NS to address the AMP. Our method outperforms existing methods particularly in tests involving cross-architectures. Moreover, owing to its adaptive nature, it exhibits enhanced stability in the face of parameter variations.
Embracing Events and Frames with Hierarchical Feature Refinement Network for Object Detection
Jul 17, 2024



In frame-based vision, object detection faces substantial performance degradation under challenging conditions due to the limited sensing capability of conventional cameras. Event cameras output sparse and asynchronous events, providing a potential solution to solve these problems. However, effectively fusing two heterogeneous modalities remains an open issue. In this work, we propose a novel hierarchical feature refinement network for event-frame fusion. The core concept is the design of the coarse-to-fine fusion module, denoted as the cross-modality adaptive feature refinement (CAFR) module. In the initial phase, the bidirectional cross-modality interaction (BCI) part facilitates information bridging from two distinct sources. Subsequently, the features are further refined by aligning the channel-level mean and variance in the two-fold adaptive feature refinement (TAFR) part. We conducted extensive experiments on two benchmarks: the low-resolution PKU-DDD17-Car dataset and the high-resolution DSEC dataset. Experimental results show that our method surpasses the state-of-the-art by an impressive margin of $\textbf{8.0}\%$ on the DSEC dataset. Besides, our method exhibits significantly better robustness (\textbf{69.5}\% versus \textbf{38.7}\%) when introducing 15 different corruption types to the frame images. The code can be found at the link (https://github.com/HuCaoFighting/FRN).